随着大语言模型(LLM)和多模态生成式 AI 在实际业务中的全面爆发,算力底座的选型已成为企业级技术决策的核心。对于习惯了在本地利用 48GB 甚至更高显存的改装硬件来折腾开源视频生成模型或前沿 AI 项目的开发者来说,单机性能往往有着明显的物理天花板。而在企业级的大规模并发和超大参数模型(如 DeepSeek 系列)部署场景下,算力需求呈指数级上升。
2026 年初正式交付的 NVIDIA B300(Blackwell Ultra)无疑是当前算力市场的重磅破局者。本文将全面解构 B300 的核心技术规格,对比历代架构差异,并探讨其在实际生产环境中的部署策略。
一、 突破显存与算力瓶颈:Blackwell Ultra 的代际飞跃
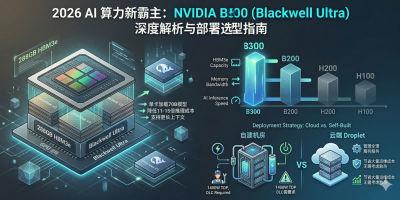
B300 并非仅仅是工艺制程的常规升级,而是 NVIDIA 针对超大规模 AI 推理痛点进行的一次底层重构。作为目前最强悍的单 GPU 计算节点,B300 的核心优势集中在三个维度:高达 14 petaFLOPS 的稀疏 FP4 算力、史无前例的 288GB HBM3e 显存,以及 8 TB/s 的极速显存带宽。
这对 AI 企业的实际工程落地意味着什么?
- 单卡承载力的大幅拓宽: 288GB 的海量显存让单张 B300 足以轻松加载 70B 参数规模的大模型(在 FP16 精度下),并且还能游刃有余地留出 100GB 以上的 VRAM 空间来应对海量并发的 KV Cache。
- 吞吐量与成本的双重优化: 相比上一代标杆 H100,B300 在大模型推理上的吞吐量实现了 11 到 15 倍的惊人跨越,大幅摊薄了单位 Token 的生成成本。
- 超长上下文的无缝支持: 突破性的显存容量从根本上解决了长文本处理时 KV Cache 挤占模型权重的窘境,保障了模型在处理极长上下文时的输出质量和响应延迟。
二、 核心规格对决:B300 vs 前代王者
为了更直观地展现性能跨度,我们来看一下 B300 与前代架构的核心参数对比:
| GPU 型号 | 核心架构 | FP8 (Dense) 算力 | 显存规格 | 显存带宽 | NVLink 带宽 |
|---|---|---|---|---|---|
| B300 | Blackwell Ultra | 7,000 TFLOPS | 288GB HBM3e | 8.0 TB/s | 1.8 TB/s |
| B200 | Blackwell | 4,500 TFLOPS | 192GB HBM3e | 8.0 TB/s | 1.8 TB/s |
| H200 | Hopper | 756 TFLOPS | 141GB HBM3e | 4.8 TB/s | 900 GB/s |
| H100 | Hopper | 756 TFLOPS | 80GB HBM3e | 3.35 TB/s | 900 GB/s |
数据不会说谎。B300 的显存容量直接翻倍于 H200,更是初代 Hopper H100 的 3.6 倍;而在关键的 FP8 推理算力上,Blackwell 架构(以 B200 为例)就已经达到了 H200 的近 6 倍。这种量级上的跃升,标志着 AI 算力基础设施正式迈入了一个全新阶段。
三、 功耗红线与基础设施重构:自建还是上云?
性能的狂飙不可避免地带来了功耗的急剧攀升。B300 的单卡 TDP(热设计功耗)飙升至 1,400W。传统的风冷机房在它面前已经捉襟见肘,直接液冷(DLC, Direct Liquid Cooling) 成为了 B300 集群的强制标配。
以一台标准的 8 卡 DGX B300 服务器为例,其峰值功耗逼近 14kW,几乎等同于两台完整配置的 H100 DGX 系统。对于企图自建算力中心的企业而言,这意味着供电系统、机架承重、冷却管路等底层基础设施需要全面推翻重来。
因此,从商业 ROI(投资回报率)和运维可行性的角度来看,将算力需求向公有云迁移成为了大多数企业的更优解。例如,DigitalOcean 等云厂商提供的 B300 GPU Droplet 实例,不仅屏蔽了底层复杂的液冷散热和电力运维难题,还能提供 25 Gbps 的内网节点间带宽和 10 Gbps 的公网带宽。配合 B300 自带的支持 1.6Tbps 带宽的 ConnectX-8 网卡,这种云端部署方案在确保大规模分布式推理通信需求的同时,有效控制了企业的前期重资产投入。
四、 总结
2026 年的 GPU 战局中,NVIDIA B300 彻底刷新了行业基准。对于正在规划下一代 AI 基础设施的团队而言,只需记住以下四个核心结论:
- 显存巅峰: 搭载 288GB HBM3e 顶级显存,单卡即可运转超大模型,治愈“显存焦虑”。
- 算力狂飙: FP8 算力高达 7000 TFLOPS,重塑并发推理吞吐极限。
- 代际碾压: 显存容量达到 H200 的 2 倍,是 H100 的 3.6 倍。
- 云端优先: 面对 1400W 的极限功耗与液冷门槛,借助成熟云平台的 B300 实例是兼顾性能与运维成本的最佳实践。