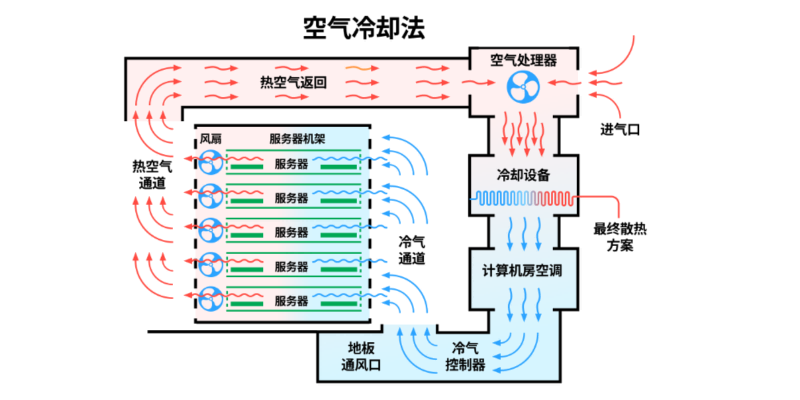
选择适合的大模型(LLM)训练 GPU 需要在算力、显存带宽、互联效率及成本之间取得平衡。以下是 NVIDIA A100、H100 和 B200 的实测与规格对比分析。
1. 核心规格与性能实测对比
| 特性 | A100 (Ampere) | H100 (Hopper) | B200 (Blackwell) |
|---|---|---|---|
| 显存容量 | 80GB HBM2e | 80GB HBM3 | 192GB HBM3e |
| 显存带宽 | 2 TB/s | 3.35 TB/s | 8 TB/s |
| FP16/BF16 训练算力 | 312 TFLOPS | 989 TFLOPS | 2,250 TFLOPS |
| FP8 训练支持 | 不支持 | 支持 | 支持(性能更强) |
| NVLink 互联带宽 | 600 GB/s | 900 GB/s | 1.8 TB/s |
| 训练性能(实测) | 基准 (1x) | A100 的 2-3 倍 | H100 的约 3 倍 |
| 典型功耗 | 400W | 700W | 1000W |
2. 实测表现与代际差异
- A100 (性价比之选): 依然是大规模分布式训练的可靠选择,尤其适合显存压力不大的中型模型(如 7B-30B)。其优势在于市场供应充足,且单卡租用成本最低。
- H100 (当前主流标配): 引入了 Transformer Engine 专门加速大模型训练。实测显示,H100 训练 Transformer 架构模型的速度比 A100 快 2-3 倍;对于 Llama 2-70B 等模型,其推理速度提升尤为显著。
- B200 (未来性能王者): 并非简单的“加强版”,而是重构的基础设施。
- 算力飞跃: 单卡算力是 H100 的 2 倍以上,训练性能提升约 3 倍。
- 海量显存: 192GB 的超大显存配合 8TB/s 的带宽,使得单台 B200 节点可以承载以往需要多台服务器才能运行的超大规模参数模型(如万亿级模型)。
- 能效: 尽管功耗高达 1000W,但在处理同等规模任务时,其能耗比显著优于前代。
3. 如何选择适合您的 GPU?
- 初创团队/中小型模型微调: 优先选择 A100 (80GB)。成本可控,且能满足绝大多数 70B 以下模型的微调需求。
- 主流 LLM 预训练与深度优化: 推荐 H100。它是目前性价比与性能平衡最好的选择,Transformer Engine 的支持让其在主流框架中表现优异。
- 万亿参数模型/追求极致迭代速度: 首选 B200。适合需要极高互联带宽和显存吞吐的千卡、万卡级集群建设,能显著缩短超大模型的训练周期。